This is the multi-page printable view of this section. Click here to print.
Update policy
1 - Common scenarios for using table update policies
This section describes well known scenarios that use update policies. Adopt these scenarios if your circumstances are similar.
In this article, you learn about these common scenarios:
Medallion architecture data enrichment
Update policies on tables let you apply rapid transformations efficiently and are compatible with the medallion lakehouse architecture in Fabric.
In the medallion architecture, when raw data lands in a landing table (bronze layer), an update policy applies initial transformations and saves the enriched output to a silver layer table. This process cascades, where the data from the silver layer table triggers another update policy to further refine the data and hydrate a gold layer table.
The following diagram shows an example of a data enrichment update policy named Get_Values. The enriched data outputs to a silver layer table, which includes a calculated timestamp value and lookup values based on the raw data.

Data routing
A special case of data enrichment occurs when a raw data element has data that is routed to a different table based on one or more of its attributes.
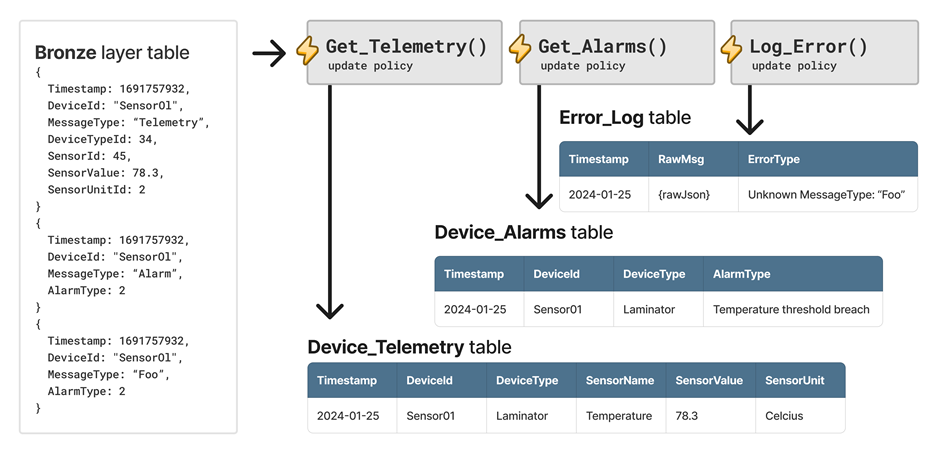
Consider an example that uses the same base data as the previous scenario, but this time, there are three messages. The first message is a device telemetry message, the second message is a device alarm message, and the third message is an error.
To handle this scenario, three update policies are used. The Get_Telemetry update policy filters the device telemetry message, enriches the data, and saves it to the Device_Telemetry table. Similarly, the Get_Alarms update policy saves the data to the Device_Alarms table. Finally, the Log_Error update policy sends unknown messages to the Error_Log table, letting operators detect malformed messages or unexpected schema evolution.
The following diagram shows the example with the three update policies.
Optimize data models
Update policies on tables are built for speed. Tables typically conform to star schema design, which supports developing data models optimized for performance and usability.
Querying tables in a star schema often requires joining tables, but table joins can cause performance issues, especially when querying large volumes of data. Flatten the model by storing denormalized data at ingestion time to improve query performance.
Joining tables at ingestion time operates on a small batch of data, reducing the computational cost of the join. This approach significantly improves the performance of downstream queries.
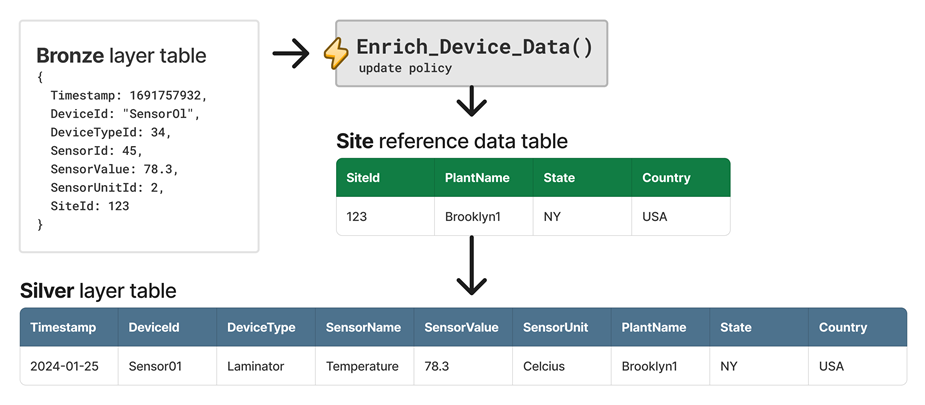
For example, enrich raw telemetry data from a device by looking up values from a dimension table. An update policy performs the lookup at ingestion time and saves the output to a denormalized table. You can also extend the output with data sourced from a reference data table.
The following diagram shows an example with an update policy named Enrich_Device_Data. This policy extends the output data with data sourced from the Site reference data table.
Related content
2 - Run an update policy with a managed identity
The update policy must be configured with a managed identity in the following scenarios:
- When the update policy query references tables in other databases
- When the update policy query references tables with an enabled row level security policy
An update policy configured with a managed identity is performed on behalf of the managed identity.
In this article, you learn how to configure a system-assigned or user-assigned managed identity and create an update policy using that identity.
Prerequisites
- A cluster and database Create a cluster and database.
- AllDatabasesAdmin permissions on the database.
Configure a managed identity
There are two types of managed identities:
System-assigned: A system-assigned identity is connected to your cluster and is removed when the cluster is removed. Only one system-assigned identity is allowed per cluster.
User-assigned: A user-assigned managed identity is a standalone Azure resource. Multiple user-assigned identities can be assigned to your cluster.
Select one of the following tabs to set up your preferred managed identity type.
User-assigned
Follow the steps to Add a user-assigned identity.
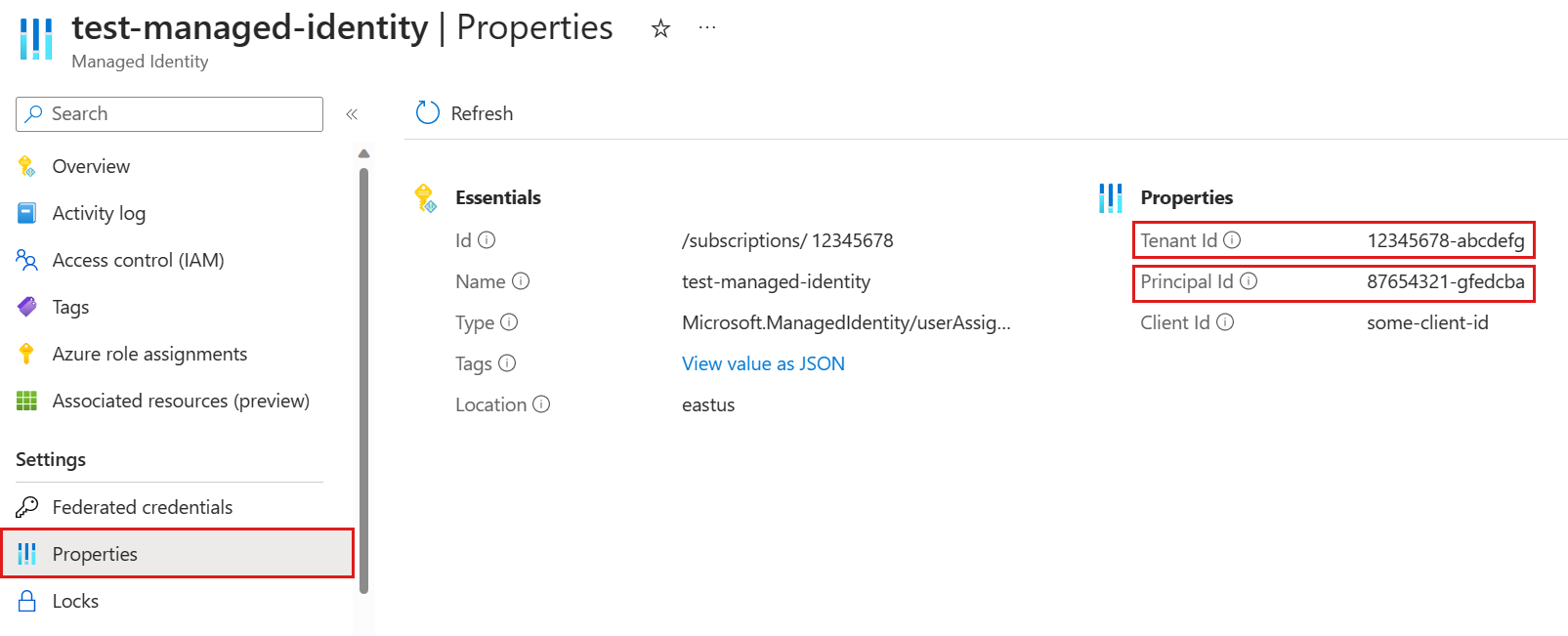
In the Azure portal, in the left menu of your managed identity resource, select Properties. Copy and save the Tenant Id and Principal ID for use in the following steps.
Run the following .alter-merge policy managed_identity command, replacing
<objectId>with the managed identity Principal ID from the previous step. This command sets a managed identity policy on the cluster that allows the managed identity to be used with the update policy..alter-merge cluster policy managed_identity ```[ { "ObjectId": "<objectId>", "AllowedUsages": "AutomatedFlows" } ]```[!NOTE] To set the policy on a specific database, use
database <DatabaseName>instead ofcluster.Run the following command to grant the managed identity Database Viewer permissions over all databases referenced by the update policy query.
.add database <DatabaseName> viewers ('aadapp=<objectId>;<tenantId>')Replace
<DatabaseName>with the relevant database,<objectId>with the managed identity Principal ID from step 2, and<tenantId>with the Microsoft Entra ID Tenant Id from step 2.
System-assigned
Follow the steps to Add a system-assigned identity.
Copy and save the Object ID for use in a later step.
Run the following .alter-merge policy managed_identity command. This command sets a managed identity policy on the cluster that allows the managed identity to be used with the update policy.
.alter-merge cluster policy managed_identity ```[ { "ObjectId": "system", "AllowedUsages": "AutomatedFlows" } ]```[!NOTE] To set the policy on a specific database, use
database <DatabaseName>instead ofcluster.Run the following command to grant the managed identity Database Viewer permissions over all databases referenced by the update policy query.
.add database <DatabaseName> viewers ('aadapp=<objectId>')Replace
<DatabaseName>with the relevant database and<objectId>with the managed identity Object ID you saved earlier.
Create an update policy
Select one of the following tabs to create an update policy that runs on behalf of a user-assigned or system-assigned managed identity.
User-assigned
Run the .alter table policy update command with the ManagedIdentity property set to the managed identity object ID.
For example, the following command alters the update policy of the table MyTable in the database MyDatabase. It’s important to note that both the Source and Query parameters should only reference objects within the same database where the update policy is defined. However, the code contained within the function specified in the Query parameter can interact with tables located in other databases. For example, the function MyUpdatePolicyFunction() can access OtherTable in OtherDatabase on behalf of a user-assigned managed identity. <objectId> should be a managed identity object ID.
.alter table MyDatabase.MyTable policy update
```
[
{
"IsEnabled": true,
"Source": "MyTable",
"Query": "MyUpdatePolicyFunction()",
"IsTransactional": false,
"PropagateIngestionProperties": false,
"ManagedIdentity": "<objectId>"
}
]
```
System-assigned
Run the .alter table policy update command with the ManagedIdentity property set to the managed identity object ID.
For example, the following command alters the update policy of the table MyTable in the database MyDatabase. It’s important to note that both the Source and Query parameters should only reference objects within the same database where the update policy is defined. However, the code contained within the function specified in the Query parameter can interact with tables located in other databases. For example, the function MyUpdatePolicyFunction() can access OtherTable in OtherDatabase on behalf of your system-assigned managed identity.
.alter table MyDatabase.MyTable policy update
```
[
{
"IsEnabled": true,
"Source": "MyTable",
"Query": "MyUpdatePolicyFunction()",
"IsTransactional": false,
"PropagateIngestionProperties": false,
"ManagedIdentity": "system"
}
]
```
3 - Update policy overview
Update policies are automation mechanisms triggered when new data is written to a table. They eliminate the need for special orchestration by running a query to transform the ingested data and save the result to a destination table. Multiple update policies can be defined on a single table, allowing for different transformations and saving data to multiple tables simultaneously. The target tables can have a different schema, retention policy, and other policies from the source table.
For example, a high-rate trace source table can contain data formatted as a free-text column. The target table can include specific trace lines, with a well-structured schema generated from a transformation of the source table’s free-text data using the parse operator. For more information, common scenarios.
The following diagram depicts a high-level view of an update policy. It shows two update policies that are triggered when data is added to the second source table. Once they’re triggered, transformed data is added to the two target tables.
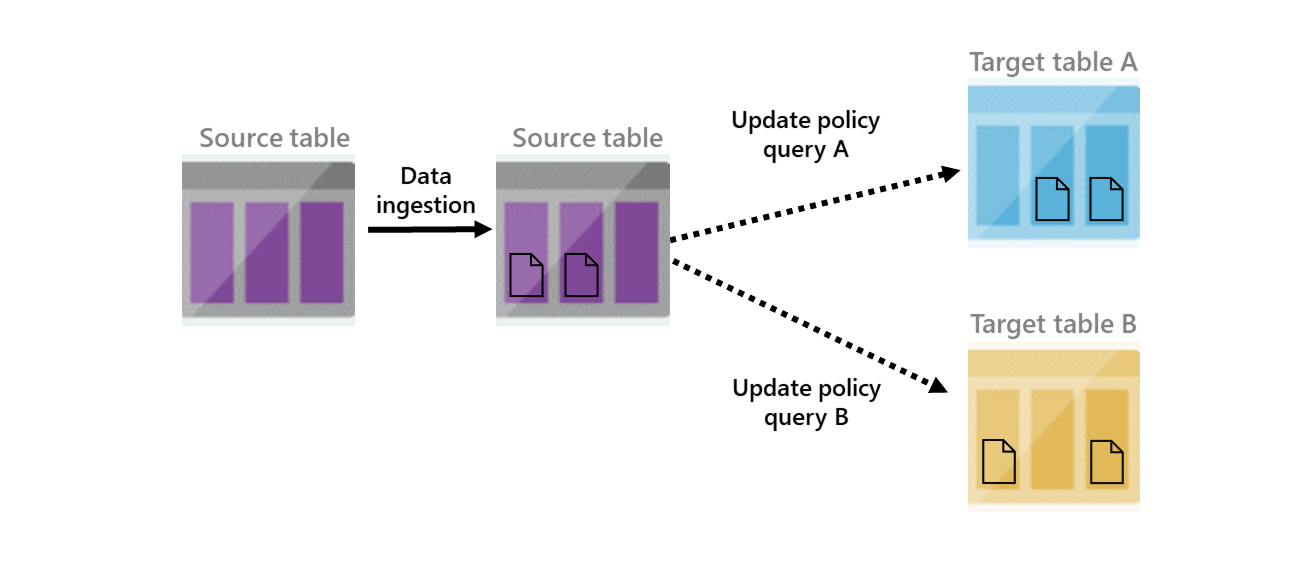
An update policy is subject to the same restrictions and best practices as regular ingestion. The policy scales-out according to the cluster size, and is more efficient when handling bulk ingestion. An update policy is subject to the same restrictions and best practices as regular ingestion. The policy scales-out according to the Eventhouse size, and is more efficient when handling bulk ingestion.
Ingesting formatted data improves performance, and CSV is preferred because of it’s a well-defined format. Sometimes, however, you have no control over the format of the data, or you want to enrich ingested data, for example, by joining records with a static dimension table in your database.
Update policy query
If the update policy is defined on the target table, multiple queries can run on data ingested into a source table. If there are multiple update policies, the order of execution isn’t necessarily known.
Query limitations
The policy-related query can invoke stored functions, but:
- It can’t perform cross-cluster queries.
- It can’t access external data or external tables.
- It can’t make callouts (by using a plugin).
The query doesn’t have read access to tables that have the RestrictedViewAccess policy enabled.
For update policy limitations in streaming ingestion, see streaming ingestion limitations.
The update policy’s query shouldn’t reference any materialized view whose query uses the update policy’s target table. Doing so might produce unexpected results.
The policy-related query can invoke stored functions, but:
- It can’t perform cross-eventhouse queries.
- It can’t access external data or external tables.
- It can’t make callouts (by using a plugin).
The query doesn’t have read access to tables that have the RestrictedViewAccess policy enabled.
By default, the Streaming ingestion policy is enabled for all tables in the Eventhouse. To use functions with the
joinoperator in an update policy, the streaming ingestion policy must be disabled. Use the.altertableTableNamepolicystreamingingestionPolicyObject command to disable it.The update policy’s query shouldn’t reference any materialized view whose query uses the update policy’s target table. Doing so might produce unexpected results.
When referencing the Source table in the Query part of the policy, or in functions referenced by the Query part:
Don’t use the qualified name of the table. Instead, use
TableName.Don’t use
database("<DatabaseName>").TableNameorcluster("<ClusterName>").database("<DatabaseName>").TableName.Don’t use the qualified name of the table. Instead, use
TableName.Don’t use
database("<DatabaseName>").TableNameorcluster("<EventhouseName>").database("<DatabaseName>").TableName.
The update policy object
A table can have zero or more update policy objects associated with it. Each such object is represented as a JSON property bag, with the following properties defined.
| Property | Type | Description |
|---|---|---|
| IsEnabled | bool | States if update policy is true - enabled, or false - disabled |
| Source | string | Name of the table that triggers invocation of the update policy. |
| SourceIsWildCard | bool | If true, the Source property can be a wildcard pattern. See Update policy with source table wildcard pattern |
| Query | string | A query used to produce data for the update. |
| IsTransactional | bool | States if the update policy is transactional or not, default is false. If the policy is transactional and the update policy fails, the source table isn’t updated. |
| PropagateIngestionProperties | bool | States if properties specified during ingestion to the source table, such as extent tags and creation time, apply to the target table. |
| ManagedIdentity | string | The managed identity on behalf of which the update policy runs. The managed identity can be an object ID, or the system reserved word. The update policy must be configured with a managed identity when the query references tables in other databases or tables with an enabled row level security policy. For more information, see Use a managed identity to run a update policy. |
| Property | Type | Description |
|---|---|---|
| IsEnabled | bool | States if update policy is true - enabled, or false - disabled |
| Source | string | Name of the table that triggers invocation of the update policy |
| SourceIsWildCard | bool | If true, the Source property can be a wildcard pattern. |
| Query | string | A query used to produce data for the update |
| IsTransactional | bool | States if the update policy is transactional or not, default is false. If the policy is transactional and the update policy fails, the source table isn’t updated. |
| PropagateIngestionProperties | bool | States if properties specified during ingestion to the source table, such as extent tags and creation time, apply to the target table. |
Management commands
Update policy management commands include:
.show table *TableName* policy updateshows the current update policy of a table..alter table *TableName* policy updatedefines the current update policy of a table..alter-merge table *TableName* policy updateappends definitions to the current update policy of a table..delete table *TableName* policy updatedeletes the current update policy of a table.
Update policy is initiated following ingestion
Update policies take effect when data is ingested or moved to a source table, or extents are created in a source table. These actions can be done using any of the following commands:
- .ingest (pull)
- .ingest (inline)
- .set | .append | .set-or-append | .set-or-replace
- .move extents
- .replace extents
- The
PropagateIngestionPropertiescommand only takes effect in ingestion operations. When the update policy is triggered as part of a.move extentsor.replace extentscommand, this option has no effect.
- The
Update policy with source table wildcard pattern
Update policy supports ingesting from multiple source tables that share the same pattern, while using the
same query as the update policy query. This is useful if you have several source tables, usually sharing the same schema (or a subset of columns that share a common schema), and you would like to trigger ingestion to a
single target table, when ingesting to either of those tables. In this case, instead of defining multiple
update policies, each for a single source table, you can define a single update policy with wildcard as Source.The Query of the update policy must comply with all source tables matching the pattern.
To reference the source table in the update policy query, you can use a special symbol named $source_table. See example in Example of wild card update policy.
Remove data from source table
After ingesting data to the target table, you can optionally remove it from the source table. Set a soft-delete period of 0sec (or 00:00:00) in the source table’s retention policy, and the update policy as transactional. The following conditions apply:
- The source data isn’t queryable from the source table
- The source data doesn’t persist in durable storage as part of the ingestion operation
- Operational performance improves. Post-ingestion resources are reduced for background grooming operations on extents in the source table.
Performance impact
Update policies can affect performance, and ingestion for data extents is multiplied by the number of target tables. It’s important to optimize the policy-related query. You can test an update policy’s performance impact by invoking the policy on already-existing extents, before creating or altering the policy, or on the function used with the query.
Evaluate resource usage
Use .show queries, to evaluate resource usage (CPU, memory, and so on) with the following parameters:
- Set the
Sourceproperty, the source table name, asMySourceTable - Set the
Queryproperty to call a function namedMyFunction()
// '_extentId' is the ID of a recently created extent, that likely hasn't been merged yet.
let _extentId = toscalar(
MySourceTable
| project ExtentId = extent_id(), IngestionTime = ingestion_time()
| where IngestionTime > ago(10m)
| top 1 by IngestionTime desc
| project ExtentId
);
// This scopes the source table to the single recent extent.
let MySourceTable =
MySourceTable
| where ingestion_time() > ago(10m) and extent_id() == _extentId;
// This invokes the function in the update policy (that internally references `MySourceTable`).
MyFunction
Transactional settings
The update policy IsTransactional setting defines whether the update policy is transactional and can affect the behavior of the policy update, as follows:
IsTransactional:false: If the value is set to the default value, false, the update policy doesn’t guarantee consistency between data in the source and target table. If an update policy fails, data is ingested only to the source table and not to the target table. In this scenario, ingestion operation is successful.IsTransactional:true: If the value is set to true, the setting does guarantee consistency between data in the source and target tables. If an update policy fails, data isn’t ingested to the source or target table. In this scenario, the ingestion operation is unsuccessful.
Handling failures
When policy updates fail, they’re handled differently based on whether the IsTransactional setting is true or false. Common reasons for update policy failures are:
- A mismatch between the query output schema and the target table.
- Any query error.
You can view policy update failures using the .show ingestion failures command with the following command:
In any other case, you can manually retry ingestion.
.show ingestion failures
| where FailedOn > ago(1hr) and OriginatesFromUpdatePolicy == true
Example of extract, transform, load
You can use update policy settings to perform extract, transform, load (ETL).
In this example, use an update policy with a simple function to perform ETL. First, we create two tables:
- The source table - Contains a single string-typed column into which data is ingested.
- The target table - Contains the desired schema. The update policy is defined on this table.
Let’s create the source table:
.create table MySourceTable (OriginalRecord:string)Next, create the target table:
.create table MyTargetTable (Timestamp:datetime, ThreadId:int, ProcessId:int, TimeSinceStartup:timespan, Message:string)Then create a function to extract data:
.create function with (docstring = 'Parses raw records into strongly-typed columns', folder = 'UpdatePolicyFunctions') ExtractMyLogs() { MySourceTable | parse OriginalRecord with "[" Timestamp:datetime "] [ThreadId:" ThreadId:int "] [ProcessId:" ProcessId:int "] TimeSinceStartup: " TimeSinceStartup:timespan " Message: " Message:string | project-away OriginalRecord }Now, set the update policy to invoke the function that we created:
.alter table MyTargetTable policy update @'[{ "IsEnabled": true, "Source": "MySourceTable", "Query": "ExtractMyLogs()", "IsTransactional": true, "PropagateIngestionProperties": false}]'To empty the source table after data is ingested into the target table, define the retention policy on the source table to have 0s as its
SoftDeletePeriod..alter-merge table MySourceTable policy retention softdelete = 0s
Example of wild card update policy
The following example creates an update policy with a single entry on table TargetTable. The policy references all tables matching pattern SourceTable* as its source.
Any ingestion to a table which matches the pattern (in local database) will trigger the update policy, and ingest data to TargetTable, based on the update policy query.
Create two source tables:
.create table SourceTable1(Id:long, Value:string).create table SourceTable2(Id:long, Value:string)Create the target table:
.create table TargetTable(Id:long, Value:string, Source:string)Create a function which will serve as the
Queryof the update policy. The function uses the$source_tablesymbol to reference theSourceof the update policy. UseskipValidation=trueto skip validation during the create function, since$source_tableis only known during update policy execution. The function is validated during the next step, when altering the update policy..create function with(skipValidation=true) IngestToTarget() { $source_table | parse Value with "I'm from table " Source | project Id, Value, Source }Create the update policy on
TargetTable. The policy references all tables matching patternSourceTable*as its source..alter table TargetTable policy update ```[{ "IsEnabled": true, "Source": "SourceTable*", "SourceIsWildCard" : true, "Query": "IngestToTarget()", "IsTransactional": true, "PropagateIngestionProperties": true }]```Ingest to source tables. Both ingestions trigger the update policy:
.set-or-append SourceTable1 <| datatable (Id:long, Value:string) [ 1, "I'm from table SourceTable1", 2, "I'm from table SourceTable1" ].set-or-append SourceTable2 <| datatable (Id:long, Value:string) [ 3, "I'm from table SourceTable2", 4, "I'm from table SourceTable2" ]Query
TargetTable:TargetTableId Value Source 1 I’m from table SourceTable1 SourceTable1 2 I’m from table SourceTable1 SourceTable1 3 I’m from table SourceTable2 SourceTable2 4 I’m from table SourceTable2 SourceTable2